




In the previous post in the series we looked at how to implement the 'Wait for a Callback' Service Integration Pattern using task tokens and the CDK.
However, we only considered what happens if everything goes to plan. As you might have heard somewhere, everything fails all the time and step functions and task tokens are no different.
This post covers the various ways our previous application could fail, and then how we might handle those scenarios. All the code can be downloaded and run by cloning the companion repo.
TL:DR
- Specify a value for
timeouton asynchronous tasks - Catch
TaskTimedOuterrors - Use
sendTaskFailureto call back with an error - Use the context
$$to log debug information with errors
Exploring the failure modes
Below is a diagram that shows the step in our state machine that makes an external service call and then waits for a task token to continue. When the service calls back via a webhook, a task token is retrieved and then used to restart the state machine.
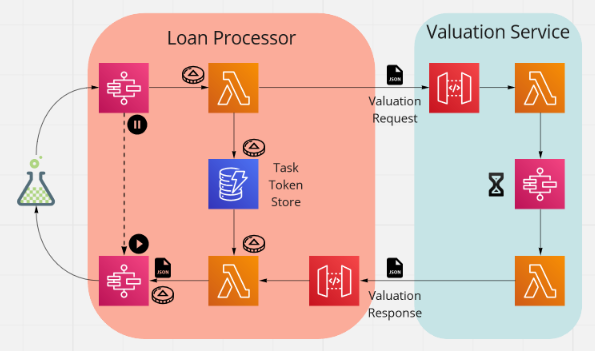
As with any piece of software, we need to consider the ways in which things could fail. It is all too easy to just consider the happy path and then be surprised when something goes wrong. Especially if you are left scratching your head, as you don't have the information to understand and fix it.
With this in mind, let us list out some ways the integration with the valuation service could fail:
- It could fail to respond.
- It could return a response that indicates it couldn't fulfil the request.
- It could return a reference that we do not expect.
Now we have our failure modes, let us consider how we can handle them in such a way that we can easily identify what went the problem was.
Timeouts and heartbeats
The first failure we will consider is where the valuation service fails to respond. If we do nothing, then our step function will stay stuck on the same step. Looking at the step function quota documentation, this will be the maximum execution time of one year.
Clearly, this is not what we want. Thankfully, the solution is quite straightforward. What we need to do is to add a timeout to the asynchronous step, as shown below.
const requestValuationTask = new LambdaInvoke(this, 'RequestValuation', {
lambdaFunction: valuationRequestFunction,
integrationPattern: IntegrationPattern.WAIT_FOR_TASK_TOKEN,
payload: TaskInput.fromObject({
taskToken: JsonPath.taskToken,
'loanApplication.$': '$',
}),
timeout: Duration.seconds(30), // Don't wait forever for a reply
});
At first I thought that it was necessary to also set a value for
heartbeat. It was only when writing this post that I consulted the 'Task state timeouts and heartbeat intervals' documentation and found that this wasn't the case for our example. Theheartbeatsetting is only required if the task is sending heartbeat notifications to indicate it is still progressing.
Our example includes a mock valuation service. To test the timeout, we update this mock service so that, if it receives a certain request, then it returns without initiating the callback.
if (valuationRequest.property.nameOrNumber === 'No callback') {
return {
statusCode: 201,
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(valuationRequestResponse),
};
}
With this code in place, we can write a unit test to send a request with 'No callback' as the nameOrNumber and then see what happens. The result is shown below.
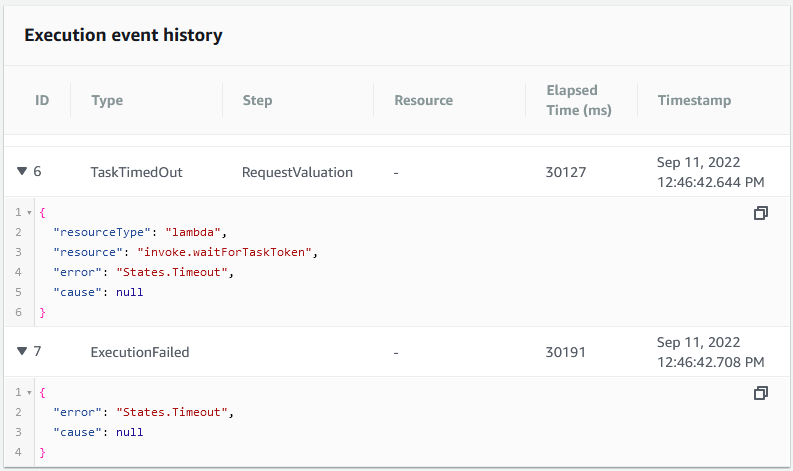
Now we know that our step function will not wait for year before failing. However, it does raise another question. What happens if our step function has timed out just before the response comes back from the valuation service?
Handling late responses
To find out what happens, we turn again to our mock valuation service. This service uses an Express Workflow to add a delay before sending the mock response as shown below.
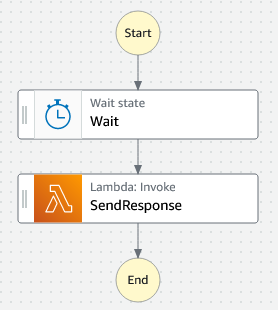
What we can do is vary the wait time depending on the valuation request. We do this by passing in a delay into the state machine as follows.
const stateMachineData: ValuationStateMachineData = {
...valuationRequest,
valuationReference,
delaySeconds:
valuationRequest.property.nameOrNumber === 'Late callback' ? 60 : 6,
};
We then bind the Wait step to the delay value.
"Wait": {
"Type": "Wait",
"SecondsPath": "$.delaySeconds",
"Next": "SendResponse"
}
With this in place, we can write another unit test to send such a request with 'Late callback' as the nameOrNumber and then run it to see what happens. What we find is the following error being thrown by the Lambda function when it tries to restart the step function.
{
"errorType": "TaskTimedOut",
"errorMessage": "Task Timed Out: 'Provided task does not exist anymore'",
"code": "TaskTimedOut",
"message": "Task Timed Out: 'Provided task does not exist anymore'",
"stack": [
"TaskTimedOut: Task Timed Out: 'Provided task does not exist anymore'",
" at Request.extractError (/var/runtime/node_modules/aws-sdk/lib/protocol/json.js:52:27)",
" at <snip>",
" at Request.callListeners (/var/runtime/node_modules/aws-sdk/lib/sequential_executor.js:116:18)"
]
}
So now we know what to expect when the service either doesn't reply or doesn't reply in time. What about the scenario when we get called more than once with the same task token?
Handling duplicate responses
A duplicate response could occur when we use any service that promises an 'at least once' delivery, such as EventBridge. This means that we could receive the same message more than once. Given this, let us look at what happens when the same task token is used more than once.
To do this, we amend the mock valuation service to send two responses when we send a request with 'Duplicate response' in the payload. By running another unit test, we then that we get another TaskTimedOut error.
{
"errorType": "TaskTimedOut",
"errorMessage": "Task Timed Out: 'Provided task does not exist anymore'",
"code": "TaskTimedOut",
"message": "Task Timed Out: 'Provided task does not exist anymore'",
"stack": [
"TaskTimedOut: Task Timed Out: 'Provided task does not exist anymore'",
" at Request.extractError (/var/runtime/node_modules/aws-sdk/lib/protocol/json.js:52:27)",
" <snip>",
" at Request.callListeners (/var/runtime/node_modules/aws-sdk/lib/sequential_executor.js:116:18)"
]
}
This means that we use the error to tell the difference between the duplicate scenario and the late scenario. If it is important to us to know the difference, say we want to ignore such duplicates, then we could extend our DynamoDB table that holds the task tokens. We could add a property to record if the token has been used, then check that before trying to use it.
Now we have investigated various failure scenarios, let us look at how might we handle them.
Notifying ourselves of failure
In my blog post Better logging through technology, I ask developers to see logging through the eyes of support. That is, put yourself in the position where something has gone wrong and you need to work out what.
In our case, we know that the valuation service step throws a States.Timeout error when the timeout is exceeded. What we will do is amend the step function to publish an SNS message to an error topic. This will give us flexibility to subscribe to this topic and do a range of actions, such as email.
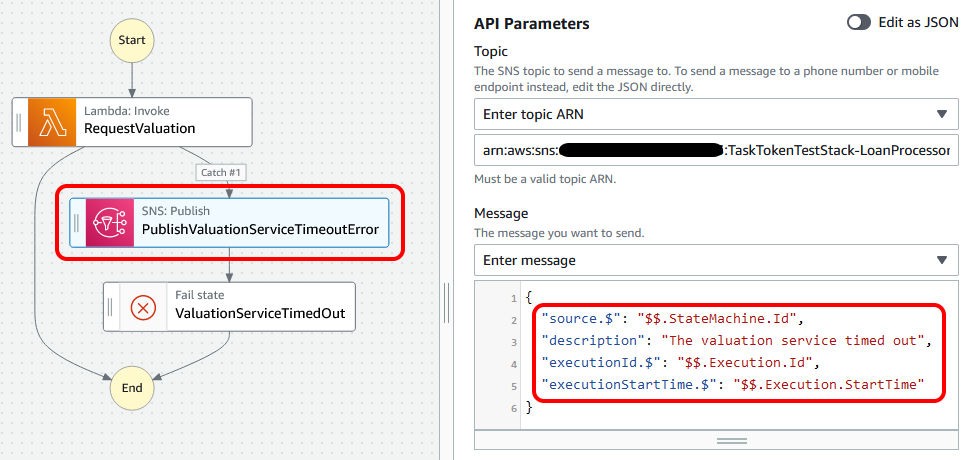
When things do go wrong, we want to be as helpful to those on support as we can. This means sending information that will allow someone to go directly to the thing that failed. For this, we are using the Step Function Context object.
By using the $$ prefix, we can publish useful information along with our message. In this case, the ids of the state machine and the execution along with the start time of the execution. This information can then be used to identify exactly what has failed and when. Then the investigations can begin.
To handle the scenario where the service doesn't reply in time, we can add a try/catch in the Lambda function and have that publish the error to our error topic. In this case, we use the AWS Lambda context object in Node.js to get hold of the function ARN.
} catch (error: any) {
const publishError: PublishInput = {
Message: JSON.stringify({
source: context.invokedFunctionArn,
description: error.message,
eventRequestId: event.requestContext.requestId,
eventBody: event.body,
}),
TopicArn: errorTopicArn,
};
await sns.publish(publishError).promise();
}
Here we try to keep to a convention of having a source and description, along with error-specific values. A bit of consistency is never a bad thing.
Handling failed requests
There is another task token failure scenario, and that is when we want to restart the step function with a failure. In our example, the valuation service can call back with a response that indicates that it failed. In this case, we want our step function to exit and inform us that it failed.
The way we do this is by using the task token, but using the sendTaskFailure method. With this, we can restart the step function with an error as follows.
const taskFailureOutput = await stepFunctions
.sendTaskFailure({
taskToken: taskTokenItem.taskToken,
error: 'ValuationFailed',
})
.promise();
We then add another catch to the step function, to handle the ValuationFailed error and publish an SNS message to inform us.
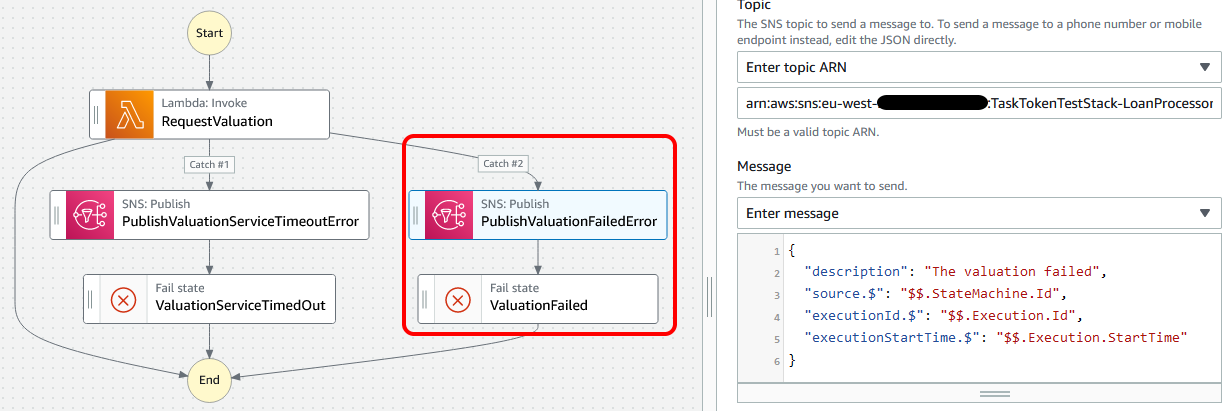
Summary
In this post, we have seen a variety of ways that we can experience failures when dealing with task tokens and step functions. We saw how we can add a timeout to prevent a task from waiting a year to fail. We also saw how we can pass back a failure state to the step function and how we can handle these errors in the flow. Finally, we saw how we can notify ourselves with context information that could help ourselves to diagnose the source of any errors.